Por Juan Morón Audante1

Hace pocos días, Elon Musk advirtió al mundo que los datos con los que se entrenan a los modelos de Inteligencia Artificial se están agotando. En realidad, esta advertencia ya la había hecho ILya Sutskever, cofundador de OpenAI, hace algunos años atrás.
Estas advertencias han sido elevadas a la categoría de teoría. Llamándola “teoría de pico de datos” o “Peak Data”. Según el cofundador de OpenAI, “estamos en un punto de inflexión. Hemos alcanzado el ‘pico de datos’. Es decir, el punto en el que no hay nuevos datos disponibles en cantidades suficientes para mejorar aún más los modelos existentes [de IA]”2
Debemos prestarle atención a estas advertencias?
Difícil respuesta. Sobre todo, porque sabemos que la cantidad de datos que se produce cada segundo en el mundo es inconmensurable. Más aún, si tenemos en cuenta que estamos entrando a una etapa en que el IoT, el desarrollo de la tecnología 5G y la revolución de los sensores producirán muchos más datos de los que pueden ser procesados. Por ejemplo, en el 2021 se estimó que la cantidad de datos generados en el mundo eran alrededor de 79 zeta bytes y se espera que este año, 2025, se producirán poco más de 180 zeta bytes3. Ver Gráfica N° 1
Figura N° 1
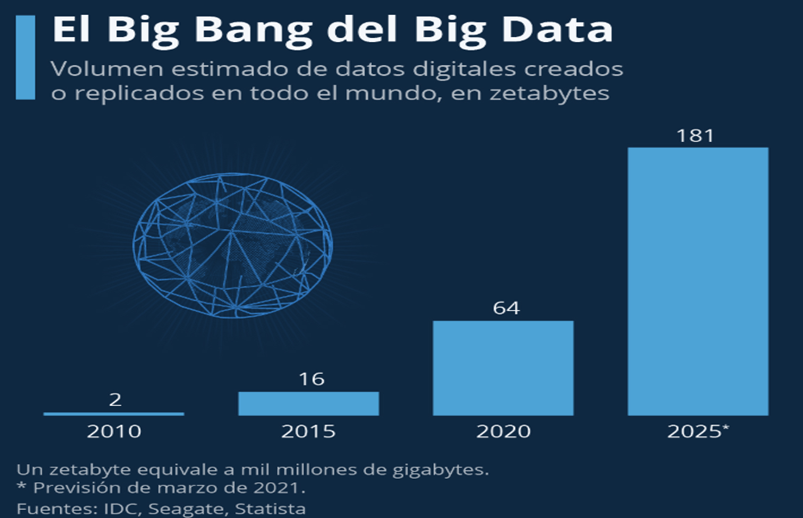
El problema es que cuando leemos o escuchamos que en el mundo se produce esta cantidad de datos, en realidad, no tenemos la más mínima idea de qué es lo que se está diciendo. Veamos. Si un zeta bytes es mil millones de terabytes y cada terabytes fuera un libro de 500 páginas, 180 zeta bytes serían suficientes para llenar 360 billones de libros. Si tomamos en cuenta que, actualmente, la biblioteca del Congreso de los Estados Unidos, la más grande del mundo, posee 40 millones de libros, entonces 180 zeta bytes equivaldrían a tener 9 millones de bibliotecas norteamericanas.
Por otro lado, muchos podrían decir que internet produce miles de millones de datos cada segundo; sin embargo, “se estima que solo una fracción muy pequeña de los datos generados en internet es realmente útil para entrenar los modelos de IA. Porque para ello, los datos deben ser de alta calidad, relevantes y bien etiquetados para ser efectivos en el entrenamiento de esos modelos”. Lo que no pasa con los datos de internet. En consecuencia, no se trata de datos per se, sino de datos adecuados a las exigencias de los requerimientos de entrenamiento de los modelos de IA4. Entonces, esto ya nos va aclarando el panorama. Quiere decir que, cuando Sustkever o Must hablan del Peak Data, se están refiriendo a que cierto de tipo de datos son los que se están agotando y no los datos en general.
Dónde está la clave de este problema?
NO son los datos per se, sino los datos que permiten mejorar los modelos de IA. Es decir, se trata que los modelos de IA MEJOREN. Entonces para eso se requiere que los datos tengan determinadas características que no todos los datos tienen. Esa es la cuestión de fondo. Porque “sin datos nuevos y relevantes, el desarrollo [de la IA] podría detenerse”5.
Por qué el agotamiento de los datos?
En realidad, no solo se trata de la ingente cantidad de datos que requiere el entrenamiento de los modelos de IA, sino también, de las restricciones que están comenzando a adoptar los sitios web sobre sus textos, imágenes y vídeos cada vez que son requeridos para los entrenamientos de los modelos. Los que algunos analistas de informática han denominado “crisis emergente en el consentimiento de los datos”6. En gran medida, como parte de consideraciones de carácter éticas y legales respecto del uso de datos públicos por parte de la IA. Así, por ejemplo, entre abril de 2023 y abril 2024, las fuentes web restringieron el 5 % de todos los datos y el 25 % de los datos de las fuentes de mayor calidad7.
El Problema, es que al ritmo en el que vienen siendo requeridos los datos para la mejora de los modelos de IA, los desarrolladores se podrían quedar sin datos entre 2026 y 20328. Es decir, esto podría ocurrir a la vuelta de la esquina. Sin embargo, erróneamente, esta situación de agotamiento de datos reales, podríamos llevarnos a creer que sin ellos el desarrollo de la IA podría detenerse. Lo cual no va a pasar, porque para eso están los datos sintéticos.
Cuál es la alternativa para enfrentar esta situación de carencia de datos calificados para seguir entrenando los Modelos de IA? Aquí es donde emerge la figura de los datos sintéticos. Se refieren a un conjunto de datos generados artificialmente, a través de procesos matemáticos y estadísticos. Para determinados analistas, este proceso no solo se trataría de un cambio tecnológico, sino también de un cambio económico. Entrenar modelos de IA con este tipo de datos es tremendamente mucho más barato que hacerlo con datos reales. Por ejemplo, el costo de entrenar modelos avanzados de ChatGPT puede llegar a los 100 millones de dólares. Pero esta cifra que nos parece exorbitante, palidece con los costos de datos para futuros entrenamiento de los modelos de IA. Según las proyecciones, se podrían requerir entre 10 y 100 mil millones de dólares9 para futuros entrenamiento de los modelos de IA.
Por esta razón, ya hay empresas tecnológicas que están utilizando este tipo de datos. Por ejemplo, Microsoft, está utilizando datos sintéticos para entrenar su modelo Phi-4. Google, emplea datos generados artificialmente para su modelo Gemma; Meta, también usa datos sintéticos para sus modelos Llama. O, el caso de la empresa Anthropic que también usa datos sintéticos para su sistema Clude 3.5 Sonnet. Mientras ChatGPT gasta 100 millones para entrenar sus modelos de IA, empresas como Write, una startup que ha desarrollado su modelo Palmyra X004, lo ha entrenado con 700,000 dólares10. Es decir, no hay comparación en términos de gastos.
Los modelos de IA entrenados con datos reales son mejores que lo entrenados con datos sintéticos?
A primera vista podríamos vernos inclinados a creer que los modelos de IA entrenados con datos reales genera mejores resultados. Es decir, modelos más eficientes que los modelos entrenados con datos sintéticos; sin embargo, no es así. Porque en realidad depende de los objetivos que se persigan con uno o con otros. A continuación podremos comparar las diferencias que se consiguen al entrenar los modelos de IA al usar datos reales y datos sintéticos.
DATOS REALES:
VENTAJAS
Precisión, los datos reales reflejan situaciones del mundo real, lo que hace que los modelos sean más precisos y relevantes
Variedad, los datos reales suelen tener mayor variedad y complejidad, lo que hace que los modelos puedan generalizar las situaciones que reflejan mucho mejor
Credibilidad, los modelos entrenados con datos reales suelen ser más creíbles y confiables
DESVENTAJAS
Disponibilidad, la obtención de grandes cantidades de datos reales es difícil y costoso
Privacidad, los datos reales pueden contener información sensible, lo que platea preocupaciones sobre la privacidad y seguridad
Sesgo, los datos reales suelen contener sesgos inherentes que se transmiten a los modelos de entrenamiento
DATOS SINTÉTICOS
VENTAJAS
Generación Controlada, los datos sintéticos se pueden generar en grandes cantidades y de manera controlada, lo que facilita la creación de un conjunto de datos balanceados
Privacidad, No contiene información sensible, lo que elimina las preocupaciones sobre la privacidad
Costo, Generar datos sintéticos puede ser mucho más económico que recolectar datos reales
DESVENTAJAS
Realismo, los datos sintético pueden no capturar todas las complejidades y variaciones del mundo real. Lo cual termina afectando la precisión del modelo
Generalización, los modelos entrenados con datos sintéticos pueden tener dificultades para generalizar a las situaciones del mundo real
Credibilidad, los resultados obtenidos de modelos entrenados con datos sintéticos pueden ser menos creíbles
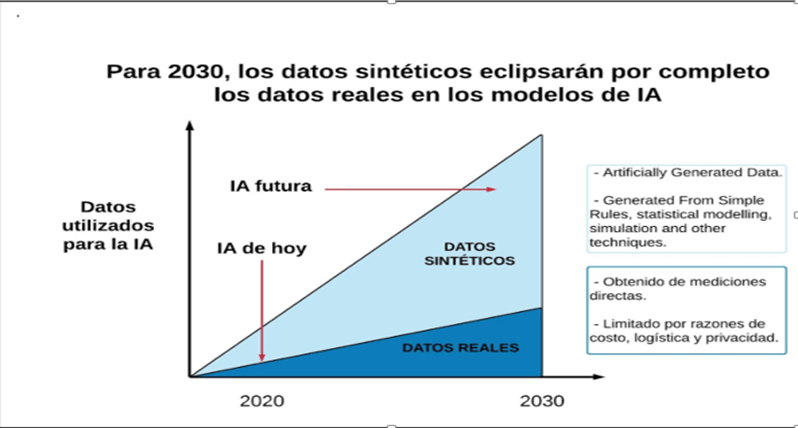
Tal es la importancia de los datos sintéticos que, según Gartner, estos datos eclipsarán a los datos reales para 2030. Además, el impacto ya es visible en la medida que algunas nuevas empresas están capitalizando esta innovación11. En consecuencia, el desarrollo de la IA no se va a detener. En cualquier caso, esto no vendrá por el lado de los datos. Ver Gráfica.
- Director del Proyecto: jma-technology; correo: jma.technology2@gmail.com; ↩︎
- https://observer.com/2024/12/openai-cofounder-ilya-sutskever-ai-data-peak ↩︎
- https://es.statista.com/grafico/26031/volumen-estimado-de-datos-digitales-creados-o-replicados-en-todo-el-mundo/ ↩︎
- https://es.shaip.com/blog/the-only-guide-on-ai-training-data-you-will-need-in/ ↩︎
- https://alphaavenue.ai/es/revista/tecnologia/pico-de-datos-ilya-sutskever-sobre-el-futuro-de-la-ia/ ↩︎
- https://observer.com/2024/07/ai-training-data-crisis/ ↩︎
- https://observer.com/2024/07/ai-training-data-crisis/ ↩︎
- Villalobos, Pablo y otros (2024);»Nos quedaremos sin datos? Límites del escalado LLM basado en datos generados por humanos». Versión original: » Will We run off data? Limits of LLM scaling base on human – generated data». En https://arxiv.org/2211.04325 ↩︎
- https://www.cryptopolitan.com/es/los-costos-de-los-modelos-de-entrenamiento-de-ia/ ↩︎
- https://www.semana.com/tecnologia/articulo/elon-musk-advierte-que-no-hay-mas-datos-para-seguir-entrenando-a-la-ia-hemos-llegado-al-limite/202528/
↩︎ - https://squeezegrowth.com/es/synthetic-data-generation-tools/ ↩︎
